Yoiur text in full, barring the caveats and the aliens:
In your first sentence you declare that we are only talking about the retinal image, in the second you discuss the absolute nature of two photos you display for visual comparison (with the eyes, you must use human cognitive function to see them). Both photos are entirely 2D and so as a facsimile are identical, you can prove it by an overlay. In the third sentence you expand this to cover 3D data and explicitly discuss our perception, i.e. after we process the information and make a prediction of what that perception is. In the third paragraph you declare that human perception is irrelevant because the 2D photos you showed are the same. Conveniently forgetting that you've expanded the data to predict 3D data and that if you performed the same two photos using 3D data rather than the 2D sign then they would be different.
Here you talk exclusively about perception, "what is seen when viewing", "when viewing the image from". You unmistakably use the model of linear geometry to predict what we should we see when we line up a 2D image with a 3D scene when viewing with the human eye. You link perception directly to linear geometry without making any allowance for the fact that the two items being viewed are fundamentally different or that the comparison is made with the data after we process the information.
OK, I haven't read everything (or even close), but let me summarize my opening sentence above. It seems that Tom has used language that Andrew has interpreted (and I'm not saying "interpreted wrongly, by the way -- I mean "interpreted in a way Tom did not intend") as including how the brain processes information, which Tom never intended, even though his language may have lead to such an interpretation.
Specifically, Tom said:
My conclusions are not about how we process the information, they are about the information itself (the light rays that enter our eyes), before we process that information.
Again, maybe how he phrased it lead to a different interpretation, but let's take Tom at his word here, and move from this point in the discussion. As for me, I find it sufficient to understand that, for a given scene and framing (even if that framing is achieved through cropping), the only way to change the perspective is to take the photo from a different position (or, perhaps, use a different focal point, but I'm thinking that even if that does affect perspective, the effect on foreground and background blur would significantly outweigh any differences in perspective).
So, if we're all on the same page, then, can we please shift the discussion to politics instead? 😁
You continue to misunderstand and misrepresent what I said. I will go through it sentence by sentence.
It is not necessary to use human cognitive function to see that two photos are the same. Computer software can easily compare the images and tell you they are the same.
All photos are entirely 2D.
I think what you mean to say is that the photos are of a flat surface perpendicular to the optical axis.
When we look at the photo, probably most people will agree that it is a photo of a flat surface with text on it. However, it requires human cognitive function to determine that.
What I actually said was: "a person looking at them will perceive the same for both. If they perceive depth in one, they will perceive the same depth in the other."
For example, if they think one is a flat surface with text on it, they will think the other is a flat surface with text on it. If they think one is a road leading away into the distance, they will think the other is a road leading away into the distance.
This is nonsense. I haven't "expanded the data" or done anything else to the photos. The photos are exactly the same as they always were: 2D photos of a 3D world. The situation I chose is particularly simple because the subject is a flat surface, everything in the frame being at the same distance from the camera.
However, remember that the two photos were taken from different camera positions, so the taking perspective is different for the two photos, yet the resultant images are the same for this particular situation.
Hence the perspective seen by the viewer of the photos will be the same, despite the camera positions being different.
I am not going to continue because you then quote from something I said 7 months ago in a different context. Please stick to what I said in the OP and not cherry-pick snippets from a different thread. It is not directly relevant. I could answer the points you raise, but not here as they are likely to just muddy the waters still further.
This is the key point, is it not? There are many people who say that 'perspective' is solely a matter of subject-to-camera distance. What you are showing is that for this subject the perceived perspective is the same even though the subject-to-camera distance is different. This is an old discussion, and comes down to a discussion about the semantics of the word 'perspective'. For my part I think that when I wrote 'perceived perspective' above it was a tautology.
Yes, but I think everyone understands that premise.
That's an interesting observation. That is, the distance from the target to the sensor varies across the target, and, as a percent, would vary less the further the camera was from the target. However, I'm thinking that the lens ideally projects a perfectly scaled flat image, so, in the case of a "perfect" lens, this would not be an issue. But, maybe that's not true. Someone with some knowledge of that might be able to elaborate.
In this scenario, the image from a lens perfectly corrected for rectilinear projection (all straight lines render as straight lines) should not be affected by the differences in distance to the sensor. A rectilinear wideangle lens would make nearby 3D objects look stretched toward the edges and corners, but not a 2D plane. The way the projection works, it should exactly compensate for the increasing distance of portions of the plane from the sensor by making those areas progressively 'bigger' in the image.
Here's a practical example (with an imperfect 18mm equivalent lens corrected in post to something approaching perfect). Distances to the edges and corners of the scene are very different from the distance to the center, but the board itself doesn't show the effect.
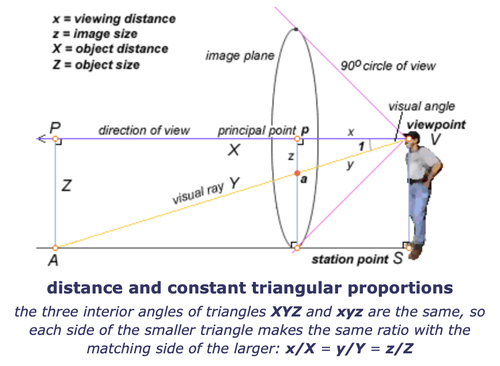
Good observation. For this reason, artists analysing perspective usually define the object distance, not as the line of sight distance, but as the component of distance measured along the optical axis (i.e. perpendicular to the plane of the image).
I have followed the same convention. The distance of a flat surface (perpendicular to the axis) from the camera means the distance along the axis, not the line of sight distance to a particular point on the surface.
What we have here is a long and final reply, though I will read replies and take them seriously. Hopefully this is all well communicated. Please take note of it. Bye bye and fare well, hope your forum continues.
I think you are all still missing the point here. So the conclusions are about the information itself and not about how we process that information. Absolutely fine if they were. First we will address this simple point:
If you look at something you are making visual comparisons between two object after we process that information, plain and simple. If you use visual example as proof of mathematical fact then you must assess how the human visual system affects your results. I have not seen any of you do this, you all just agree that they are mathematically the same and look the same so therefore... There's one heck of a lot of assumption in there.
So how does viewing the examples in the OP of this thread affect or change what we are seeing and how would that change the results?
Well, the colour will be different because we know that the human eye doesn't see absolute colour but sort of auto W/b. Next get 10 people to read the actual text and see if they follow it exactly or paraphrase. So if we make the same mistakes on both does that mean they are still identical? Not relevant? Heck of an assumption as you're using visual comparison of mathematical fact.
Let's jump to Tom's explanation in the response below:
They are not 2D photos of a 3D scene, they are 2D photos of 2D signs.
So GB please do me the maths, concentrating entirely on the information itself, and show me this is more than nonsense. We are talking here about a copy machine, so explain what "taking perspective" is, how it is relevant, or even explain to me how you could take a photo of the two signs from any distance and make them different. Please explain how this has any relevance to the title.
I have no problem with the maths in this example. However there is a strong desire to be able to rationalize what you see by the metrics tyou know, so not only do you tend to believe what you see is the retinal image, you also tend to start analysing how you see as a series of still images.
I'll be quite clear here, you can't see your retinal image. It is always processed data and it is never the same as the absolute information presentd to the back of the retina, even when looking at 2D signs. You can't ignore this or dismiss this without considering it's affects and yet most of you seem to be doing just that. You are using the human eye to confirm that the two images are the same. So prove to me, simply, just how you came to that conclusion. And please tell me that you've actual done it because if you've just made the assumption because you know they're the same and you understand the maths to be the same, and they look the same... Then you're half way down the road to confirmation bias, if proving preconcieved theories is what this is about.
So now you've done your overlay, because as we're checking for difference between rather than from absolute data you can ignore perceptual effects.
But what does this show, or inform us about perspective? How does it relate to taking photos of a 3D scene from different camera positions? Nothing, it's a pointless exercise.
Earier in the thread I responded you your post with this (paraphrased):
This shows you part of the way human cognative function works. You do not see your retinal image, even when looking at 2D data. There is no situation as a scientist where you can fail to allow for this or consider it when using visual examples, one you have to look at.
How does this work with 2D images of 3D scenes?
Take a single image of a 3D scene. Copy it if you wish (use Tom's method above). You know it's the same, you understand how it was rendered and the maths that renders it. You can understand that if you stood in the same spot as the camera then the rendering then your retinal image would be much the same, certainly the same maths can be used to predict both.
But can you confirm this by viewing the photos, or viewing the photo when standing in the exact spot of the camera? This is relevant because in the theories that have come before and will follow from this post this is exactly what has been done and will be done again.
Same photo, different distances - You see it differently, and remember if at this point you're using the maths of linear geometry and centre of perspective to explain this that you are dealing exclusively with perception here, this is not absolute data and you are applying linear geometry directly to processed data.
Same photo - From the centre of perspective, under red bias light then under blue bias light. The same or different? Do you know or just assumed?
Ok, at this point I will also point out that all these visual examples have been posted on an internet forum where they will be viewed by a collection of intelligent people at different distances with different W/B.
Do you still think that even with 2D images in this thread that we've made adequate allowance for the nature of human cognitive function when viewing images as examples, that we have considered it's effect when drawing conclusions?
When we view the 3D world we do not see our retinal image. It is always modified and modified to make the world a more consistent place that's easier to understand, navigate and predict. It's a fact.
When we view a 2D image we always use cognitive function, the understanding of it is never a mathematical function of the image. Especially with 2D text!
Let me show you what is happening in this example of the theory of perspective that contradicts Tom's assertion above full text in context in the OP here
:
The mathematical model is quite easy to understand and based on linear geometry. If you take a photo (or slide) then use the centre of perspective as described above, then if you ray trace, from the 3D scene trough the corresponding point they would all meet at the centre of perspective. We are still talking:
But if we say:
Then we've crossed the line and are now discussion perception and therefore have to take the effect of human cognitive function into consideration. We cannot use visual example as confirmation of mathematical fact. Remember:
When we view the 3D world we do not see our retinal image. It is always modified and modified to make the world a more consistent place that's easier to understand, navigate and predict. It's a fact.
When we view a 2D image we always use cognitive function, the understanding of it is never a mathematical function of the image.
If you did see the same in the photo as the real world then it would absolutely NOT confirm linear geometry because you can't see that when using visual example to compare a photo to the real world.
Still think this is a failure to communicate, that we are still only discussing the retinal image:
The maths is fine, but your collective understanding of how we see and understand perspective both the real world and photos of it is flawed and will continue to be untill you understand the limits of geometry and take perceptual effects into account when using visual example. Seriously, you need to understand just how often you're all jumping between retinal image and human perception without realising it. I can fill at least a whole page where visual example is used to confirm mathematical fact and perceptual effects are related directly to linear geometry without any allowance for the nature of the vision used to do the comparison.
Andrew, all this is completely irrelevant. When I said "viewing the image" or "looking at the image" or "seeing the image", I meant it in a very general sense. All of the relevant characteristics of the image can be measured by a machine instead of a human being. Machine vision today is capable of detecting and measuring many properties of an image. Telephoto compression is a characteristic of perspective that can be "seen" by a machine. No human eye is needed. It is a basic mathematical property of the image.
At times I have mentioned depth perception by humans, but that is because that is the way that telephoto compression usually manifests itself to us. However, the phenomenon of telephoto compression is a direct consequence of linear perspective and can be detected by machine vision just as well as by human beings.
So, don't get hung up on the vagaries of human depth perception: that is a red herring. I was probably unwise even to mention it! It is not an essential part of the argument.
It seems that we probably agree on all the essentials.
Or are you going to find another reason (excuse?) to disagree?
It really isn't, though, if perspective isn't all that important to the "success" of your photo. Just like saying to use a wider aperture in lower light isn't stupid if DOF isn't all that important to the "success" of the photo.
I'm hoping my previous comment was deleted because of the comment at the start. If so it was a fair cop, and hopefully this one will stand.
Briefly:
Do it with a machine. If we did and were careful too look only at the retinal image and not at our perception we would find that our machine would see exactly the same image at all distances. That is it's mathematical truth, the relationships do not change. If we give our machine the correct height, width and depth (if we have memory of all then allow our machine to as well) then the only correct answer it will ever come up with is that we are looking at a magnified image of the correct perspective of a distant object.
So why don't we as humans instinctively understand the absolute mathematical truth in the image? It's a more logical and simpler deduction that what actually happens.
If we keep blindly assuming that what we see is absolute then we keep treating what we see as the retinal image. We therefore automatically try to apply the maths to describe what we see rather than how the real world should look.
It's pretty much fact that human cognitive function prevents us from seeing our retinal image. We see a composite derived form memory, from scanning the scene as we actively move through it, modifying the data to remove or clarify paradox, plus other cognitive functions. It is not and can't be condensed to ray tracing or linear geometry.
You proof says that the height of the object and the angle is subtends is a mathematical function of the image, in geometry yes. But so is the relationship between height and depth in the image, why don't we compare those as the machine does? In your proof you choose the maths that describes what you see, you subconsciously try to fit what we see to the mathematical model rather that how the world should actually look.
The proof is really in front of you. We misinterpret the distance of the object, we don't see the relationship between height and depth correctly. You're applying linear geometry to predict why we don't see the linear geometry in the image correctly.
If you do the maths we (and our machine) know that perspective renders all distant objects as foreshortened.
What do we see when we view our t-c image?
If human cognitive function prevents us from seeing our retinal image then we would have no memory of context for this foreshortened (or compressed) view. So we assume that it's height is representative of the distance as the most likely explanation for the image. Because our vision is there to make sense of the world not nonsense the way we misinterpret the rest of the information can most definitely be related to the model of linear geometry. But not exactly because we are still over the line and are talking about cognitive function and not retinal image.
That we decide to interpret the height of the object in the image as representative of it's distance from us the viewer is a choice, human cognitive function. It is not a function of the maths of the image, if it were then so is the relationship between height and depth. We choose to hold one as true and modify the other. YOur theory also fails to explain how we can adapt and learn to interpret images correctly
If we view the image at the centre of perspective then we make no error in assuming the distance and so process the data much the same way as we do in the real world, they will look very similar.
If we are prevented from seeing the world of linear geometry by our cognitive function then it must also always fail to describe how you see.
You're attempting to speak on everyone else's behalf by saying "we" when in fact you are posting just your opinion. Attempting to speak on everyone's behalf is just plain dumb.
Not everyone's eyes interact with their brain in exactly the same way.
What Tom posted in his op is consistent with my observations.